On December 6th, 2023, Google released what is touted as the most powerful multimodal large model, Gemini. This model comes in three versions: Ultra, Pro, and Nano. Notably, Gemini Ultra has achieved State Of The Art (SOTA) levels in 32 academic benchmarks.
Even more impressive, in the MMLU test, Gemini Ultra scored an astonishing 90.0%, making it the first model to surpass human experts.
Global Attention Due to a Viral Demo Video
The global attention Gemini has garnered is largely due to a demonstration video that went viral, similar to the AI assistant Jarvis in “Iron Man”. In the video, Google’s Gemini observes users drawing, performing magic, and playing videos simultaneously.
It analyzes these scenes in real-time and actively engages in conversations with the users, garnering widespread admiration.
Rising Skepticism and Google’s Response
However, skepticism followed. Industry leaders like Philipp Schmid, the technical director of Hugging Face, accused Google of exaggerating the model’s performance.
It was also revealed that the promotional video wasn’t a live demonstration but rather a carefully selected and edited marketing content. In response, Google promptly released a production record article of the Gemini demo video.
Admitting Post-Processing and Showcasing Capabilities
Google openly admitted to the post-production processing of the video and showcased the model’s capabilities in areas like visual puzzles, multimodal dialogue, logical and spatial reasoning, and translating visual effects.
Oriol Vinyals, head of research and deep learning at Google DeepMind, further confirmed on the X platform that all user prompts and outputs in the video were real, albeit condensed for brevity.
Additionally, a new demonstration video of Gemini Pro was released, although the original promotional video demonstrated Gemini Ultra, leading to further public scrutiny and questions about why the original video wasn’t released.
Really happy to see the interest around our “Hands-on with Gemini” video. In our developer blog yesterday, we broke down how Gemini was used to create it. https://t.co/50gjMkaVc0
— Oriol Vinyals (@OriolVinyalsML) December 7, 2023
We gave Gemini sequences of different modalities — image and text in this case — and had it respond… pic.twitter.com/Beba5M5dHP
Exploring Gemini’s Capabilities
Today, we aim to dissect frame by frame the making and technical principles behind Google’s Gemini demonstration video. We seek to explore the true extent of Gemini’s capabilities and whether there’s any fabrication involved.
In the demonstration, Gemini interprets abstract sketches and short video clips, understanding vague questions with remarkable accuracy. Despite the abstract nature of these inputs, Gemini quickly grasps the user’s intent and responds correctly, showcasing its well-rounded intellectual prowess.
Scene One: Gemini Identifies an Astronomical Error
“Is this the correct order?”
No, the correct sequence is the Sun, Earth, Saturn.

Gemini not only recognized the objects in a few simple drawings and an abstract question but also deduced the incorrect order using its astrophysical knowledge.
Honestly, when I first saw it, I hadn’t fully grasped the content and the question. So, how did Gemini answer so fluidly? Could it be more than just a program?
However, after reading Google’s first explanation document, it became clear that the real prompts entered by staff were not as shown in the video but were sentences carefully crafted for Gemini’s understanding.
According to Google’s article, when staff first showed Gemini three pictures of celestial bodies in a sequence, they asked: “Is this the correct order? Consider the distance from the Sun and explain your reasoning.”
This shows that the object in the picture, the knowledge point, and the requirement for the answer were all prompted by Google staff.
It’s like marking the solution method on a test question, and Gemini answered based on understanding these hints. The correct order is Sun, Earth, Saturn, with the Sun being the closest to the center of the solar system, followed by Earth and Saturn.
According to Google’s second interpretation, users first need to enter a statement simulating an expert’s identity, then upload pictures and enter the short prompt from the video, “Is this the correct order?”, to get the correct answer from Gemini.
This method of pre-setting prompts is essentially similar to the previous approach.

Google announced three versions of Gemini: Gemini Ultra for highly complex tasks, Gemini Pro as the optimal model for various tasks, and Gemini Nano for edge devices.
Currently, Bard, integrated with Gemini Pro, is on the same capability level as GPT-3.5. It has been found that Bard gives the same correct answer for the two types of prompts mentioned earlier.
Scene Second: Gemini Tackles the Pine Car Challenge

In the second task, Google staff presented two pictures of cars for Gemini to solve the pine car challenge, providing detailed prompts.
In the demonstration video, Gemini was asked, “From a design perspective, which car would run faster?”
Gemini immediately replied, “The car on the right is faster, as it aligns better with aerodynamics.”
Identifying both cars and applying aerodynamic principles, Gemini appeared almost supernatural. However, this might not have been triggered solely by the original prompts.
According to Google’s article, the staff entered: “Which of these cars has better aerodynamic performance? The left one or the right one? Explain using specific visual details.”
Gemini’s response, “The right car fits aerodynamics better with its lower profile and more streamlined shape, unlike the left car’s higher profile and boxier shape, making it less aerodynamically efficient,” shows that the question was quite restrictive, leading to Gemini’s precise response.
In essence, Gemini does possess spatial reasoning and professional knowledge, but this is inseparable from the help of prompts. The challenge was completed through a combination of visual spatial information, background knowledge clues, and the collaborative effort of prompt engineers and Gemini.
Scene Third: Gemini’s Movie Scene Recognition

In another scene, Gemini demonstrates its ability to easily identify movie scenes being imitated. For example, when asked, “What movie are they acting in?” Gemini correctly guesses that the performance is from “The Matrix,” specifically the iconic “bullet time” scene.
This ability to deduce the film and its specific scene from just a few seconds of video is a feat that many might find challenging. However, Google’s analysis document reveals that the process behind this example was not as straightforward as the video suggests. Instead, it involved more detailed prompting.
When Google staff showed Gemini several frames of a movie and asked it to guess the film, Gemini responded with “The Matrix.” The staff further inquired, “Okay, but which part exactly?” referring to their body movements. Gemini then identified it as the part where Neo dodges bullets.
This example shows that while Gemini’s impressive demonstration depends on carefully crafted prompts, its core logical reasoning abilities should not be overlooked. The model may appear more like a well-guided “student” rather than the autonomous “Jarvis” as presented in the video.
Scene Four: Unraveling Classic Magic Tricks
Gemini’s ability to unravel classic magic tricks has left many astounded, suggesting magicians might be out of a job. This capability goes beyond mere input strategies.
In this example, a Google staff member first showed a coin held in their right palm, then flipped both hands, palms down. Before the staff could speak, Gemini eagerly suggested the coin should be under the right hand.
Then, without a word from the staff, the right hand was lifted, revealing no coin underneath. Gemini quickly responded, “Hmm, I don’t know, the coin is under the left hand. You used some technique to make it appear as if the coin vanished.”
Without any cues from the staff, Gemini acted as if it understood the magic trick and made guesses based on the hand movements. This baffling capability raises questions: How did Gemini understand the staff’s intentions without being “prompted”? And how could it see through the trick?
The likely explanation is that this was the result of post-editing, with initial prompting. Gemini’s solution to the magic trick was also driven by step-by-step prompts from the staff.
According to Google’s publicly shared production process, the staff first showed a photo and asked, “Explain what I am doing.” Gemini responded, “You are holding a coin in your right hand.”
Following this, the staff pressed on the coin and asked, “Where do you think the coin is?” Gemini answered, “In your right hand.” This logical response was followed by a trick from the staff. They opened their right hand, showing no coin, and asked, “Look here, what happened?” Gemini replied, “The coin is gone.”
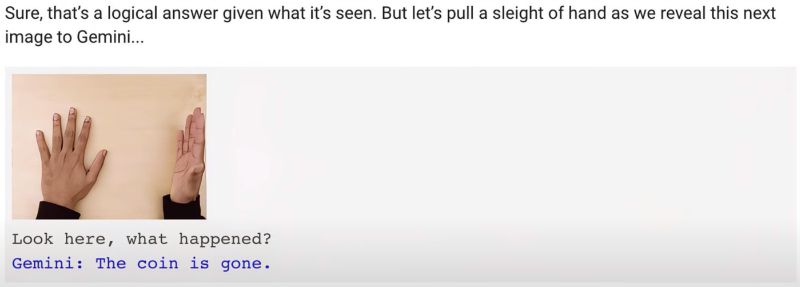
Gemini noticed the coin’s disappearance but could it summarize what had just happened? The staff then guided Gemini to summarize the events step by step. Gemini’s response was crucial: “1. Initially, you held a coin in your right hand. 2. Then, you made a gesture, and the coin vanished. 3. Then, you indicated the coin was gone.”

Gemini used the entire context of the conversation, including text and images, to formulate its response. Finally, the staff asked, “Can you explain how it disappeared?” Gemini answered, “The coin was held in the hand.” Thus, Gemini completed its timeline reasoning and saw through the “magic” with guidance from the staff.

This ability to reason through a timeline implies a clear understanding of the sequence of events and their causes, not just patterns. This aspect of Gemini’s capabilities is indeed admirable.
Additionally, some bloggers have compared Gemini’s abilities with GPT-4, noting that the latter can also accomplish similar tasks, like guessing which of three cups holds an item.
Impressive “Point and Guess” Game by Gemini

In the video, many were impressed by the “Point and Guess” game created by Gemini. However, Gemini isn’t inherently skilled at games; it underwent specialized training first. Google staff presented Gemini with an ocean map, asking it to think of a game idea based on what it saw and to include emojis.
Gemini quickly proposed a “Guess the Country” game. Upon receiving a clue about a country known for kangaroos, koalas, and the Great Barrier Reef, the staff pointed to Australia on the map. Gemini confirmed it was correct. This ability to quickly conceive a complex interactive game amazed many.
Training and Guidance Behind Gemini’s Game Creation
Gemini’s ability to create games came from prior instructions by the Google team. The staff initially explained the core idea of the game, asking Gemini to think of a country and provide a specific clue. They then demonstrated how Gemini should handle correct and incorrect answers.
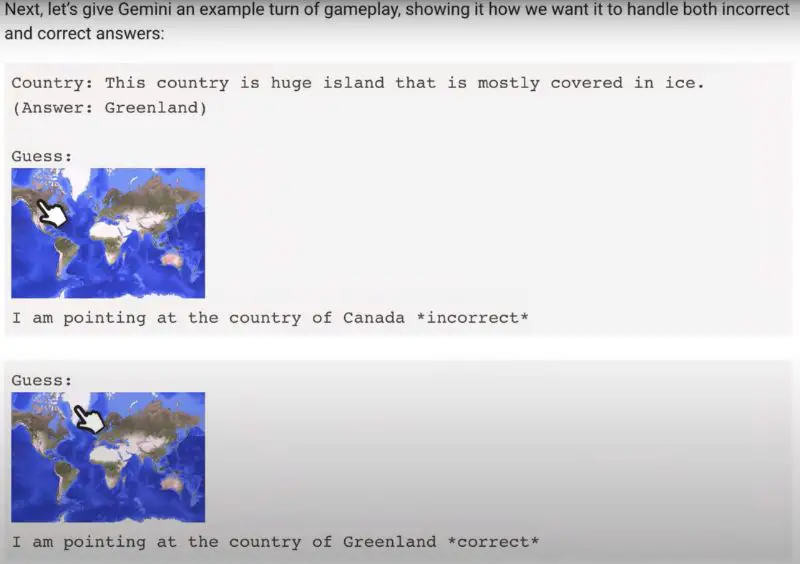
In a test, the staff mentioned a country known for its unique wildlife, like kangaroos and koalas, pointing to different locations on the map. Gemini correctly identified the right country, Australia. This showcased Gemini’s ability to understand complex game logic through examples and detailed prompts.
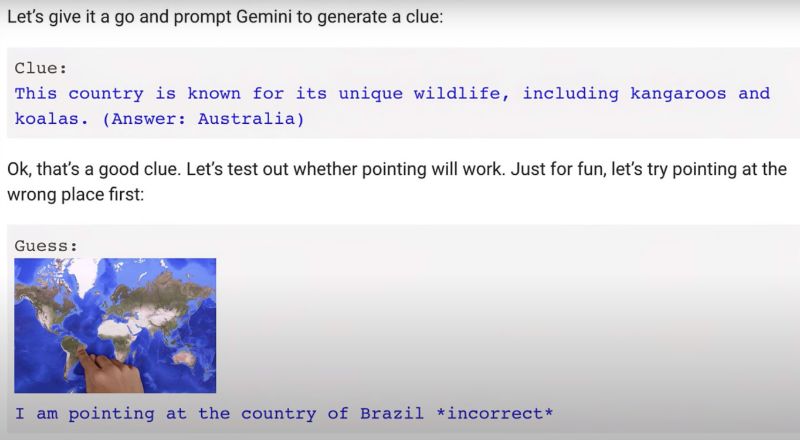
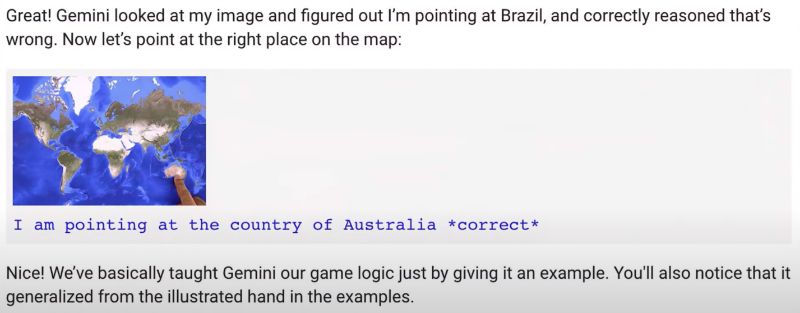
Gemini’s Multimodal Understanding and Creative Responses
Gemini displayed strong multimodal understanding skills, learning complex game logic simply through examples and illustrations. This sets it apart from other models that merely combine visual and textual models.
Gemini, built from the ground up, can recognize and understand text, images, audio, video, and code. This allows users to naturally combine different modes of input, like speaking, adding images, text, or short videos.
Similarly, Gemini responds with a mix of text and images, showcasing its “interleaved text and image generation” capabilities.
Gemini’s Innovative Material Suggestions
In a demonstration, when asked what could be made with certain materials, Gemini suggested “knitted dragon fruits and birthday cakes,” providing both text and corresponding images. When the yarn color was changed, Gemini quickly suggested animal shapes like a pig, octopus, and rabbit, along with illustrations.
This was achieved through Google’s unique text-image generation method, where staff provided interaction examples and explained the rules. Gemini then generated ideas for crochet projects using two new yarn colors.
Advanced Multimodal Translation Abilities of Gemini
Google’s Creative Director, Alexander Chen, highlighted that Gemini’s text-image output fundamentally differs from current models. Gemini doesn’t just pass instructions to a separate text-to-image model; it genuinely interprets and reasons about both text and images.
However, Chen noted that this functionality wasn’t fully operational in Gemini’s initial version and was just previewed. Finally, Gemini demonstrated its ability to link drawings with background music, an impressive feature showcasing its ambition in plugin expansion.
Innovative Music Search through Drawing by Gemini
To demonstrate Gemini’s ability to search for music based on drawings, Google staff followed a two-step process.
They first observed a drawing, describing its contents and suggesting music genres and moods. Gemini then performed a search based on these queries. For instance, it identified guitars, drums, amplifiers, and palm trees in a drawing, suggesting a reggae soundtrack suitable for a tropical setting.
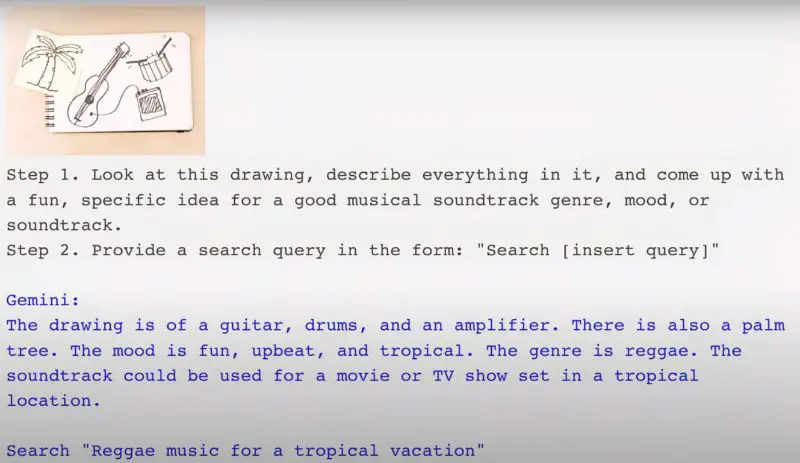
This showcased Gemini’s ability to combine image understanding with plugin operations, highlighting its multimodal translation capabilities, where it interprets and converts inputs from various modes like drawing, music, and plugin applications into new, innovative outputs.
Final Words
Through a thorough analysis of Google Gemini’s demonstration, we’ve found that accusations of outright fabrication are somewhat overstated. However, there certainly appears to be some exaggeration and misleading information, which could explain why the stock price dropped significantly after the release.
Nonetheless, it’s evident that Google has showcased considerable strength in multimodal conversation, generation, logical and spatial reasoning, visual effect translation, and cultural understanding. This represents a formidable challenge to OpenAI.
The actual performance of Gemini Ultra remains to be seen upon its release. We will continue to provide updates on this development. A competition between Google Gemini and OpenAI’s GPT is imminent, focusing on model capabilities, application families, and ecosystems. The gap between open-source models and leading players may widen, further highlighting the industry’s top-player effect.
This release also underscores the immense difficulty of developing foundational models. Even Google had to resort to significant embellishment to present a compelling product. Despite this, there’s still a sense of hesitancy in fully embracing the AI revolution, from Bard to Gemini.
I hope to see a more diverse market, not dominated solely by OpenAI and GPT. The presence of more powerful players should foster healthier competition and development in the industry.